From Prompt to Product: Turning HPU Intent into CPU Execution
BLUF: The real value of generative AI is not in the answers it gives but in the durable capability it helps you build.
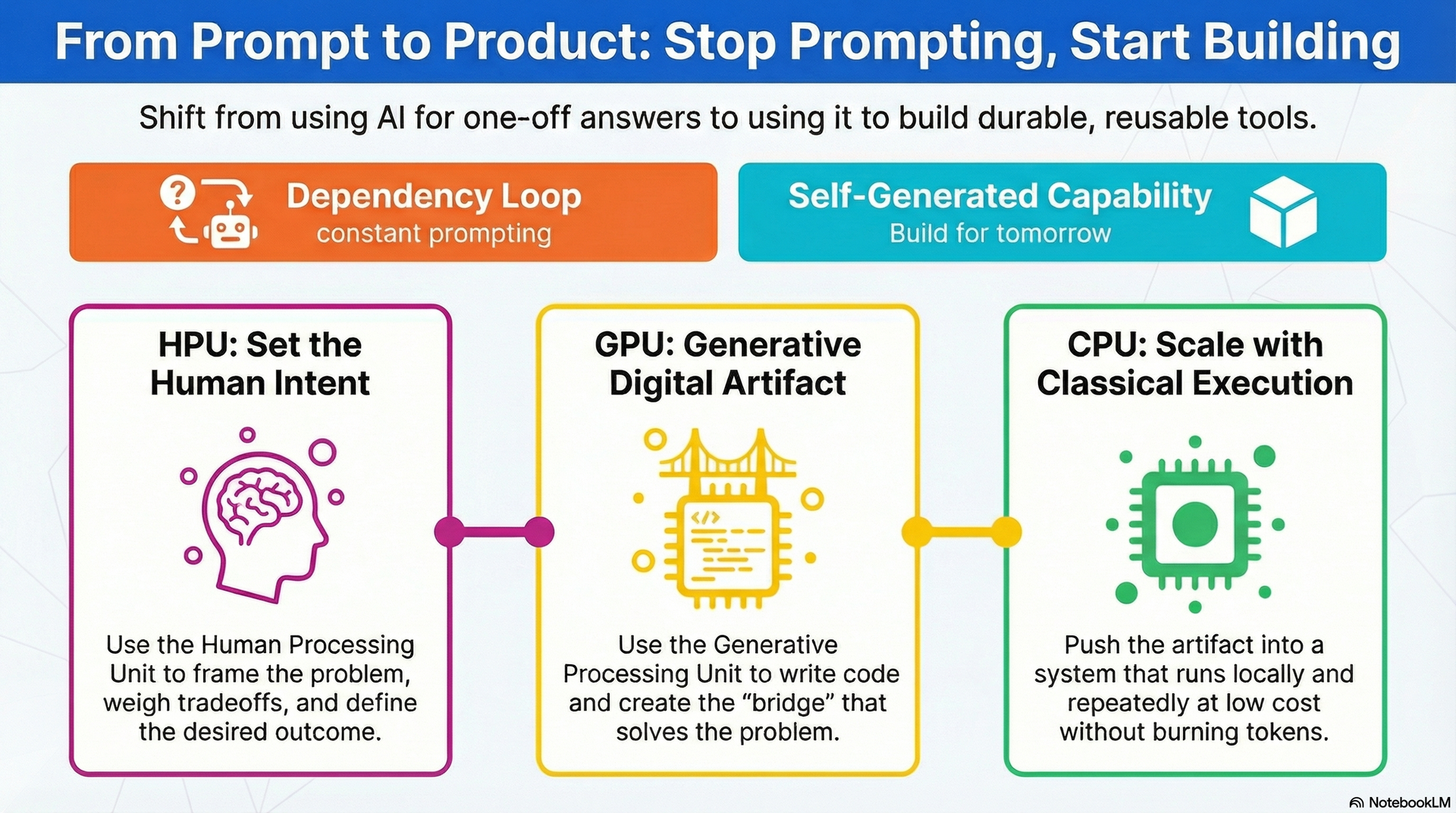
From HPU intent to CPU Execution (Image by J Eselgroth w/GenAI)
A model spent eight minutes trying to transcribe a video. It failed. Five minutes later, a simple app solved the problem permanently.
That moment stayed with me. Not because the model failed. Because it exposed how most people use generative AI. They treat it like a vending machine. Insert a prompt. Receive an answer. Move on. That pattern feels productive. It is also misleading. Real leverage is not consuming intelligence on demand. Real leverage is building something that keeps working after the model stops.
The Shift Beneath the Surface
A few weeks ago, I wrote about the new physics of productivity. Work now moves across three layers. The HPU, or Human Processing Unit, is where judgment lives. You frame the problem. You weigh tradeoffs. You set intent. The GPU, or Generative Processing Unit, is where creation happens. Code gets written. Patterns emerge. Options multiply. The CPU, or Classical Processing Unit, is where execution scales. Systems run. Workflows fire. Outputs repeat at low cost.
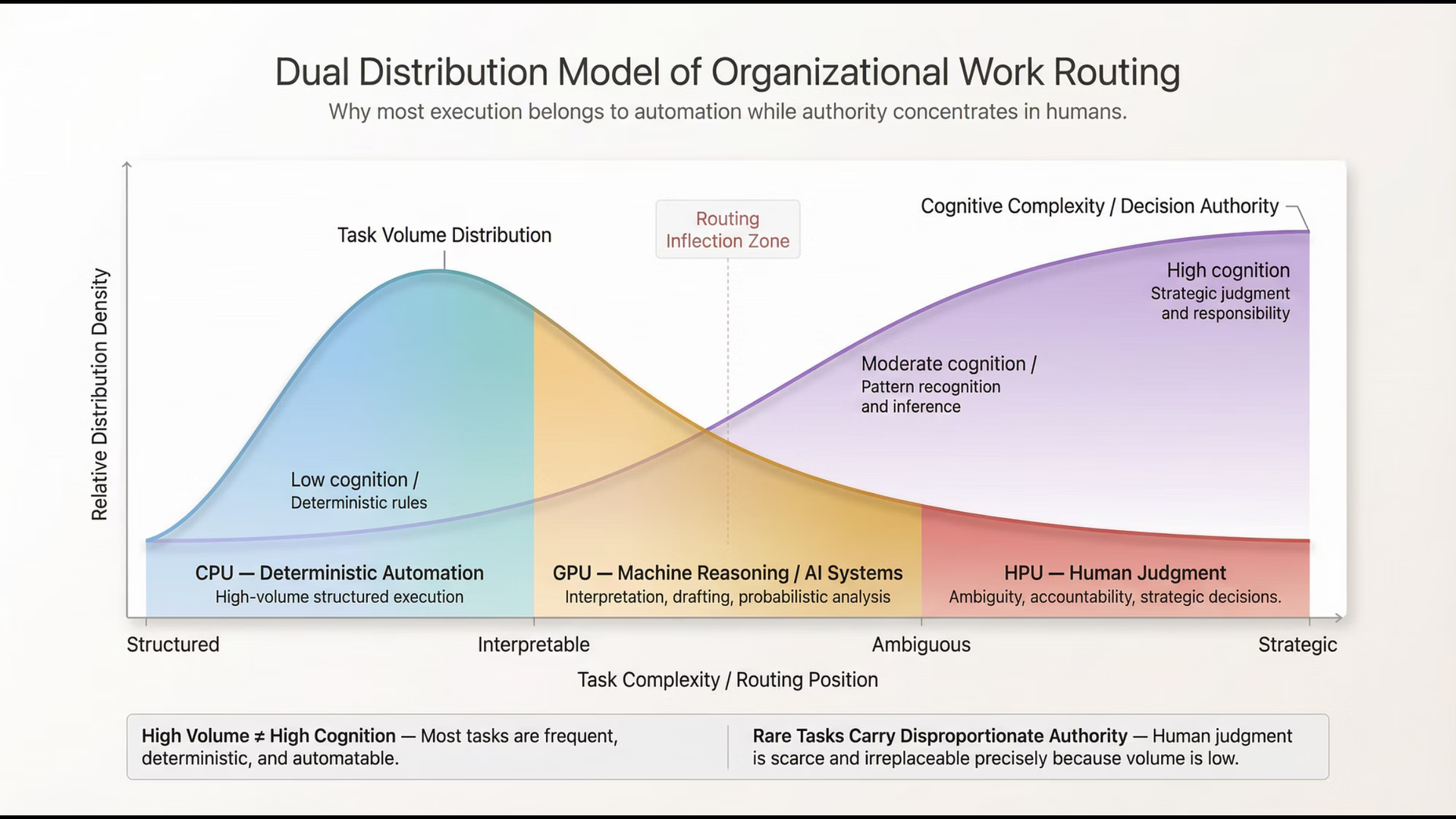
HPU, GPU, CPU, where should you route the work to? (Image by J Eselgroth w/Gen AI)
Most people move from HPU to GPU and stop. They think the answer is the outcome. It is not. The outcome is what runs after the answer.
Where Most People Stop
The pattern is familiar. Open a model. Type a prompt. Get a response. Close the tab. Every time the task returns, you repeat the cycle. Every failure costs time, tokens, and attention. That is not a workflow. That is a dependency loop.
The real opportunity sits one layer deeper. Use the HPU to frame the problem. Use the GPU to generate the artifact. Then push the result into the CPU layer. Let it run on its own. No more round trips. No more token burn. The generative layer is not the destination. It is the bridge.
"The generative layer is not the destination. It is the bridge.
A Real Example Under Pressure
I saw this play out after finishing a six-week course. I recorded each session using Google Meet. For most classes, I turned on captions. I never turned on transcripts. That turned out to be fine. The caption layer gave the models enough to work with later. But for two sessions, I forgot to enable captions entirely. That small miss created a real problem.
I needed transcripts from every recording. The first few were easy. I dropped the MP4 files into ChatGPT. It found the caption layer and returned clean text. Fast. Almost invisible. That is usually when people stop thinking about the process.
Then I hit the two files without captions. The model started searching for tools. It tried different approaches. It worked long enough to build false hope. Then it failed. I tried another model. Same result. One-hour video files are heavy. The task had become a full speech-to-text problem. The path through the model was slow, unreliable, and burning through tokens with nothing to show for it.
I was also running out of time. A family trip was hours away. Urgency sharpens your judgment fast. The wrong workflow becomes painfully obvious when the clock is moving. I started searching the internet for a solution. Some tools wanted five or ten dollars. Others were free. That kind of free always raises a question. If you are not paying, your data is the product. I did not want course recordings sitting on a random server. I did not want to create an account with a service I would never use again. None of it felt right.
So I changed the question. I stopped looking for a service. I asked for a tool. I prompted for a simple local application. Drag and drop an MP4. Extract the audio. Generate a transcript. Run it in Docker. Keep everything on my machine.
In minutes, I had a Python script, a small UI, and a working runtime. I dropped in the two problem files. The app processed them. I got the transcripts. Problem solved. Reusable.
Screenshots of my new video to transcript app
From Answer to Asset
That experience crystallized something important. Generative AI is not just an answer engine. It is a capability factory. Instead of paying for intelligence every time, you pay once. You use it to build a mechanism that keeps doing the job. You use the GPU to create something that operates at the CPU layer. That is a fundamentally different move. You are not generating answers. You are generating infrastructure.
The Economic Shift
Tokens are not free. Latency is not free. Failed attempts are definitely not free. There is also a quieter cost. Sensitive data flowing into tools you do not control. People treat these costs as minor. Each interaction feels small. But small repeated costs compound into workflow drag. They become friction. They become the tax you pay for never moving past the prompt. And most people do not even realize they are paying it.
The next productivity shift is not about better prompting. It is about knowing when to stop prompting and start building. Some tasks belong in the generative layer. Brainstorming lives there. Early drafting lives there. Exploration lives there. But repeatable tasks are different. Time-sensitive tasks are different. The moment a task shows up twice, ask whether it deserves to become a tool.
Tailorability at the Tactical Level
This connects to an idea I explored in delivering tailorability to the tactical level. For years, we designed technology around central platforms. Long implementation cycles. Vendor roadmaps. Capability was something you procured, not something you built at the edge. That logic is weakening. The person closest to the problem can now shape the solution directly. Governance still matters. Architecture still matters. But the distance between need and capability is collapsing. The edge is getting smarter, faster.
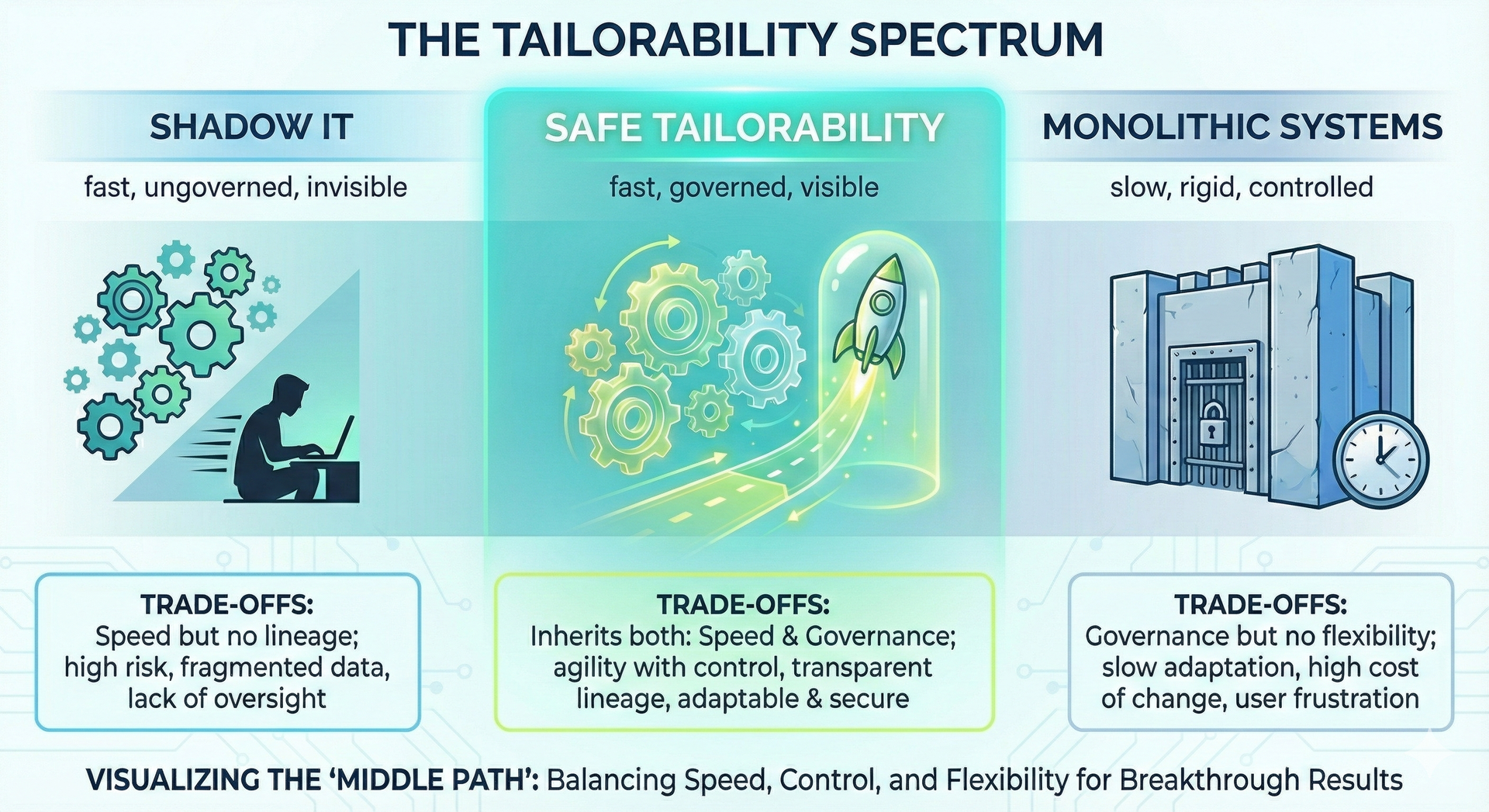
Right now, today, we are experimenting and in some cases developing production in the safe tailorability segment (Image by J Eselgroth w/GenAI)
The Trap: Tools Are Not Systems
There is a trap here worth naming. A one-off app is not a system. Solving a single problem is useful. Supporting a team or a business requires more. You need data models. Storage. Telemetry. Access controls. Transaction history. You need time-series data to support prediction and learning. Machine learning does not run on intuition. It runs on structured, historical data. If you never capture that data, you cannot improve over time. Generative tools can get you surprisingly far on the first build. But serious operating capability still requires thoughtful design.
"Machine learning does not run on intuition. It runs on structured, historical data.
Systems thinking matters more now, not less. Creation speed has increased. The need for intent and structure has not. When building is easy, knowing what should exist becomes the harder skill. Without that discipline, you end up with clever tools and no capability stack.
What Changes Next
The real shift is behavioral. Once you build your first tool, your instincts change. You stop hunting for solutions. You stop comparing subscriptions. You stop waiting for someone else to ship the feature you need. You start asking a different question. Could I just build this? And once you ask that question once and the answer is yes, you never go back to the old pattern.
That question changes everything. It moves you from consumer to builder. From passenger to operator. From someone who waits for capability to someone who generates it.
We are not entering an age of better prompts. We are entering an age of self-generated capability. The individuals and organizations that win will not be the best prompters. They will be the ones who move fastest from HPU intent, through GPU creation, into CPU execution. The model is not the product. What you build with it is.
